Hello CUDA
CPU vs CUDA 성능 비교
이 강의에서는 CPU와 GPGPU CUDA에서의 연산 속도를 비교하기 위해 아주 간단한 프로그램을 만들어 보겠습니다.
실험 개요
약 8GB 크기의 float 배열을 생성하고, 모든 요소에 10을 곱하는 연산을 CPU와 GPU에서 각각 수행하여 성능을 비교해보겠습니다.
CPU 구현
가장 간단한 방법으로 C++을 사용해 CPU에서 연산을 수행해보겠습니다. 랜덤한 float 값을 20억개의 element를 가진 vector에 assign한뒤 10을 곱하는 연산입니다.
#include <iostream>
#include <vector>
#include <chrono>
#include <random>
#include <numeric>
int main() {
constexpr uint64_t numElements = 2'000'000'000;
std::cout << "Allocating vector with " << numElements << " float elements (~8GB)..." << std::endl;
// Modern C++ random number generation
constexpr uint64_t seed = 42;
std::mt19937 gen(seed);
std::uniform_real_distribution<float> dist(0.1f, 10.0f);
// Initialize vector with random values
std::vector<float> data;
data.reserve(numElements);
std::cout << "Initializing with random values..." << std::endl;
for (uint64_t i = 0; i < numElements; ++i) {
data.emplace_back(dist(gen));
}
std::cout << "Starting computation..." << std::endl;
const auto start = std::chrono::high_resolution_clock::now();
for (auto& element : data) {
element *= 10.0f;
}
const auto end = std::chrono::high_resolution_clock::now();
const auto totalTime = std::chrono::duration<double>(end - start);
std::cout << "First and last element: " << data[0] << " " << data[numElements - 1] << std::endl;
std::cout << "Computation completed in " << totalTime.count() << " seconds" << std::endl;
return 0;
}
CPU 실행 결과

- 실행 시간: 약 0.74초
CUDA 구현
동일한 연산을 CUDA를 사용하여 GPU에서 병렬로 수행해보겠습니다.
아직 CUDA 문법이 낯설 수 있지만, 전체적인 실행 흐름을 이해하는게 목적입니다. 자세한 문법은 다음 강의에서부터 차근차근 배울 예정입니다. CPU와 똑같이 8GB사이즈의 float vector를 만들고 모든 element에 10을 곱합니다. 다만 이번에는 해당 연산은 CPU가 아닌 GPU에서 실행합니다.
#include <iostream>
#include <chrono>
#include <random>
#include <numeric>
#include <cuda_runtime.h>
// CUDA kernel to transform elements
__global__ void multiply10(float *data, int size)
{
int idx = blockIdx.x * blockDim.x + threadIdx.x;
if (idx < size) {
data[idx] = data[idx] * 10.0f;
}
}
int main()
{
constexpr uint64_t numElements = 2'000'000'000;
constexpr size_t bytes = numElements * sizeof(float);
std::cout << "Allocating " << numElements << " float elements (~8GB)..." << std::endl;
constexpr uint64_t seed = 42;
std::mt19937 gen(seed);
std::uniform_real_distribution<float> dist(0.1f, 10.0f);
float *hData = new float[numElements];
for (uint64_t i = 0; i < numElements; i++)
{
hData[i] = dist(gen);
}
float *dData = nullptr;
cudaMalloc(&dData, bytes);
cudaMemcpy(dData, hData, bytes, cudaMemcpyHostToDevice);
// Set up CUDA kernel execution
const int blockSize = 256;
const int gridSize = (numElements + blockSize - 1) / blockSize;
const auto start = std::chrono::high_resolution_clock::now();
multiply10<<<gridSize, blockSize>>>(dData, numElements);
// Wait for GPU to finish
cudaDeviceSynchronize();
const auto end = std::chrono::high_resolution_clock::now();
std::chrono::duration<double> totalTime = end - start;
// Copy result back to host
cudaMemcpy(hData, dData, bytes, cudaMemcpyDeviceToHost);
std::cout << "First and last element: " << hData[0] << " " << hData[numElements - 1] << std::endl;
std::cout << "Computation completed in " << totalTime.count() << " seconds" << std::endl;
// Clean up
cudaFree(dData);
delete[] hData;
return 0;
}
CUDA 실행 결과

- 실행 시간: 약 0.012초
- 성능 향상: CPU 대비 약 70배 빠름!
CUDA 코드 실행 과정 분석
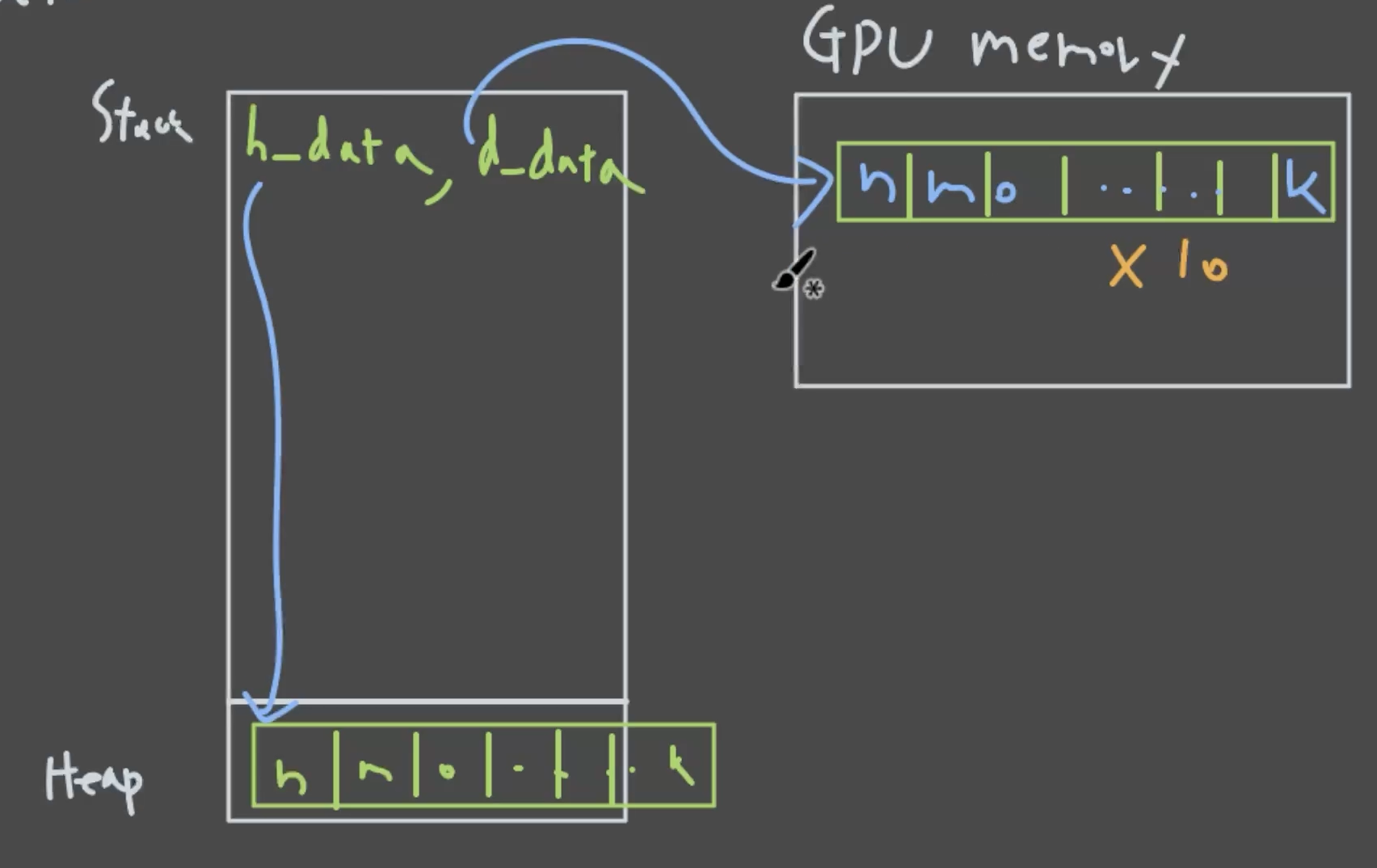
- Host 메모리 할당: CPU 메모리에 4GB 크기의 배열 생성
- 데이터 초기화: 테스트를 위해 모든 요소를 1.0으로 설정
- Device 메모리 할당:
cudaMalloc()으로 GPU 메모리에 4GB 할당 - Host → Device 복사:
cudaMemcpy()로 데이터를 GPU로 전송 - 커널 실행 설정: block size, grid size 등 병렬 실행 파라미터 설정
- 커널 실행:
multiply10<<<>>>()문법으로 GPU에서 병렬 연산 수행 - 동기화:
cudaDeviceSynchronize()로 GPU 연산 완료 대기 - Device → Host 복사: 연산 결과를 CPU 메모리로 복사
- 결과 출력: 처리된 데이터 확인
- 메모리 해제: CPU와 GPU 메모리 정리
다음강의
다음 시간에는 본격적으로 CUDA의 문법과 개념들을 자세히 알아보겠습니다.
- 커널 함수 작성법
- 스레드, 블록, 그리드 개념
- 기본적인 CUDA 프로그래밍 패턴