CUDA syntax
들어가며
이전 시간에는 CUDA 프로그램을 직접 작성하여 아주 간단히 약 70배의 가속을 실제로 만들어 보았습니다. 이제 CUDA 프로그램을 본격적으로 배울 시간인데, 한번에 어려운 내용을 배울 수는 없기 때문에 몇 개의 강의에 걸쳐서 천천히 CUDA 문법에 익숙해질 것입니다.
NVIDIA에서 제공하는 CUDA C++ Programming Guide 메뉴얼을 보면, CUDA를 어떻게 프로그래밍해야 하는지 공식적으로 알려줍니다. 하지만 이것만으로는 부족합니다.
우리가 프로그래밍을 배울 때, C나 C++ 언어만으로 모든 것을 알 수 있는 것이 아닙니다. 자료구조와 알고리즘, 그리고 컴퓨터구조, OS를 알아야 하듯이, CUDA 문법만으로는 병렬 프로그래밍을 효과적으로 만들 수 없습니다.
GPULab.kr과 함께 CUDA 문법, 그리고 자료구조 알고리즘 하드웨어까지 한번에 배우는 것이 가장 빠른 방법입니다.
CUDA예제
다시 본론으로 돌아와서 코드를 매우 간단하게 바꾸어 보겠습니다. 해당 예제는 128개의 int array를 만들어서 한번에 100씩 추가하는 코드입니다.
#include <iostream>
#include <vector>
#include <cuda_runtime.h>
__global__ void add100(int32_t* data)
{
const int idx = threadIdx.x;
data[idx] = data[idx] + 100;
}
void cpuAdd100(int32_t * data)
{
for(int32_t idx = 0 ; idx < 128 ; ++idx)
{
data[idx] = data[idx] + 100;
}
}
int main()
{
constexpr uint32_t dataLength = 128;
int32_t *hostData = new int32_t[dataLength];
for (int32_t i = 0; i < dataLength; ++i)
{
hostData[i] = i;
}
int32_t* deviceData;
cudaMalloc(&deviceData, dataLength * sizeof(int32_t));
cudaMemcpy(deviceData, hostData, dataLength * sizeof(int32_t), cudaMemcpyHostToDevice);
add100 <<<1, dataLength >>> (deviceData);
cudaDeviceSynchronize();
cudaMemcpy(hostData, deviceData, dataLength * sizeof(int32_t), cudaMemcpyDeviceToHost);
cudaFree(deviceData);
for (int32_t i = 0; i < dataLength ; ++i)
{
std::cout << hostData[i] << " ";
}
delete [] hostData;
return 0;
}
코드 분석
1. Host 메모리 할당 및 초기화
hostData의 heap 공간에 128 size를 가진 array를 만들어서 initialize를 합니다.
constexpr uint32_t dataLength = 128;
int32_t *hostData = new float[dataLength];
for (int32_t i = 0; i < dataLength; ++i)
{
hostData[i] = i;
}
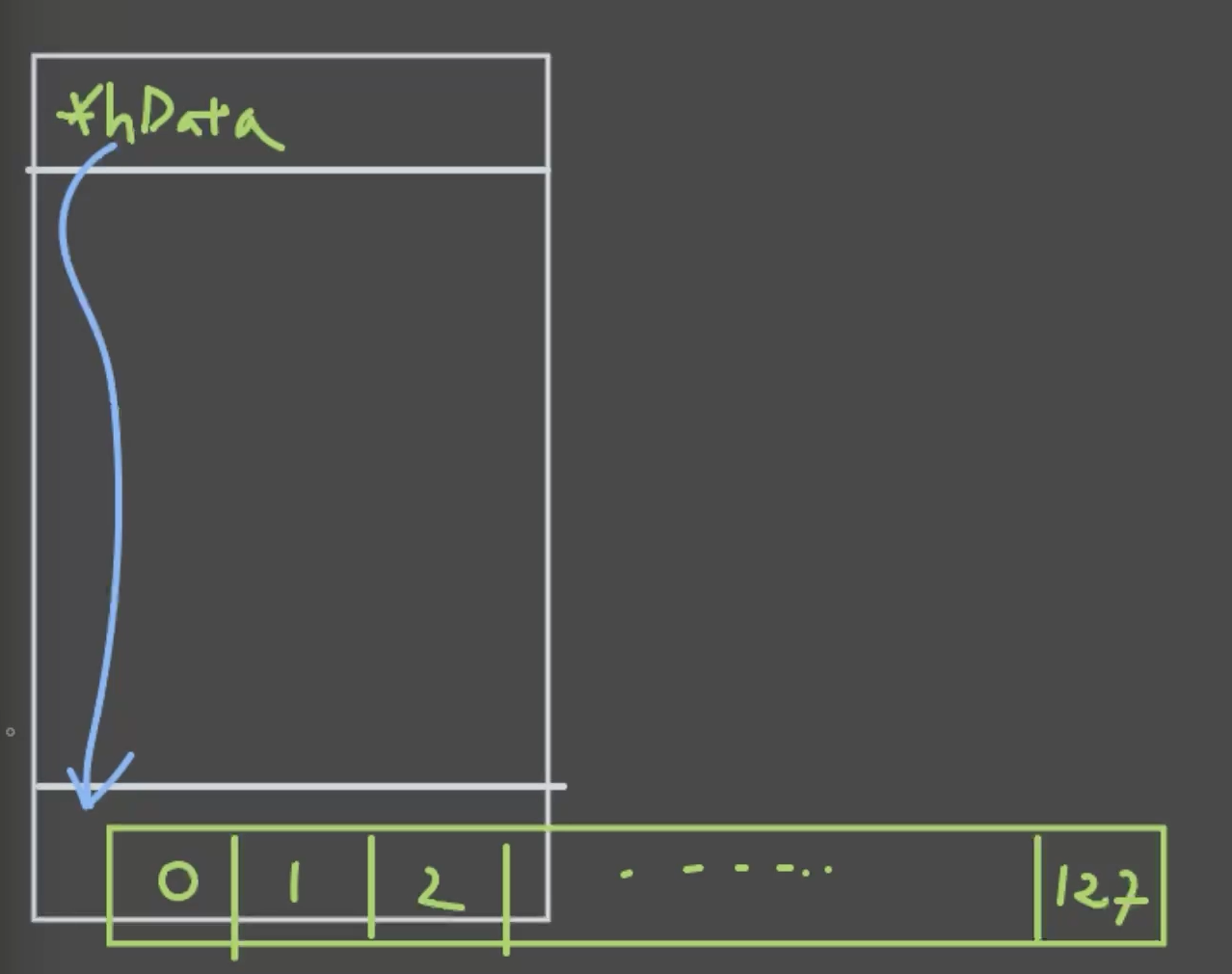
2. Device 메모리 할당
deviceData pointer를 만들어서, GPU 메모리 공간에 넣습니다
int32_t* deviceData;
cudaMalloc(&deviceData, dataLength * sizeof(int32_t));
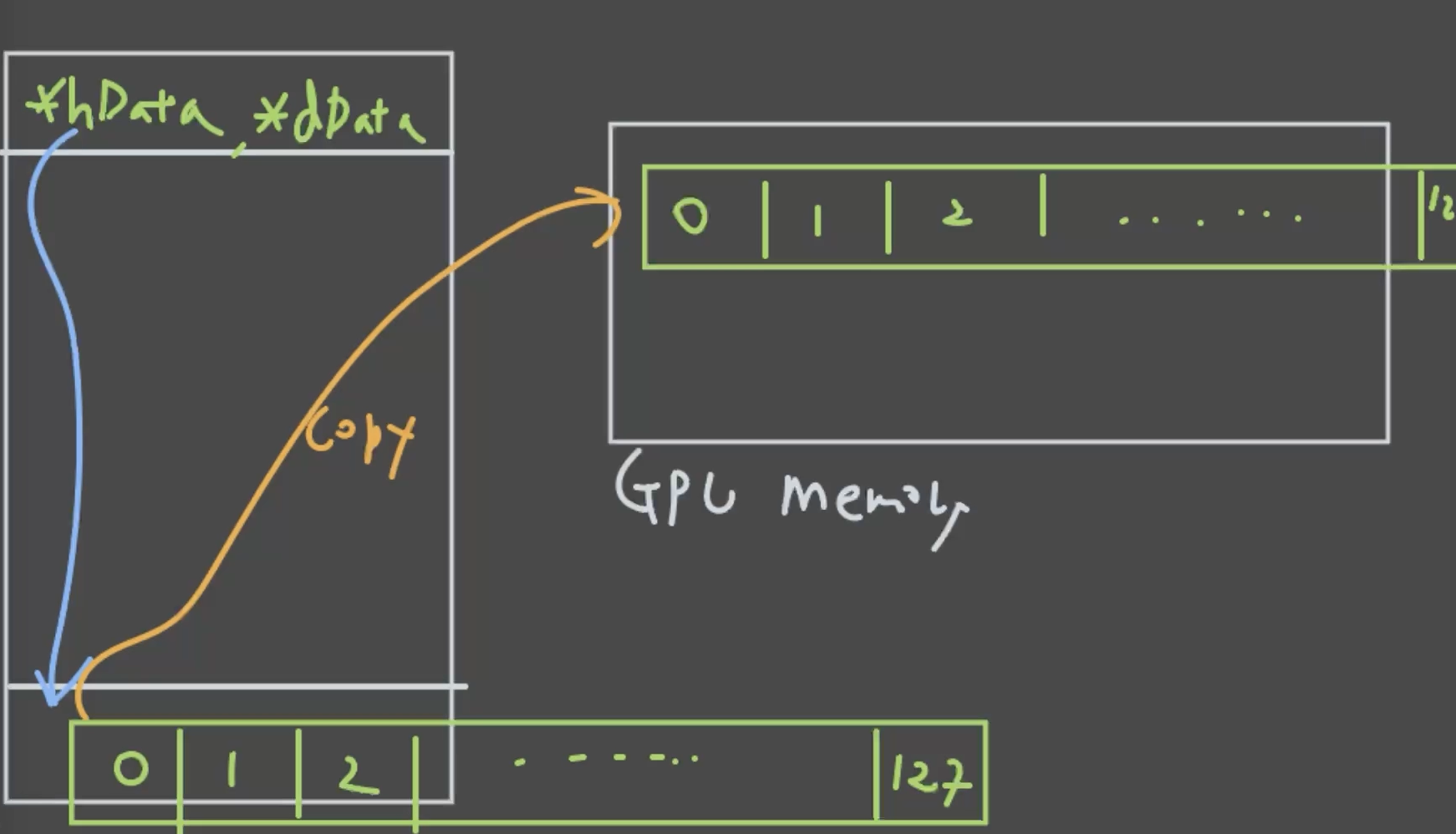
3. Host → Device 메모리 복사
hostData로부터 deviceData로 copy를 합니다.
cudaMemcpy(deviceData, hostData.data(), dataLength * sizeof(int32_t), cudaMemcpyHostToDevice);
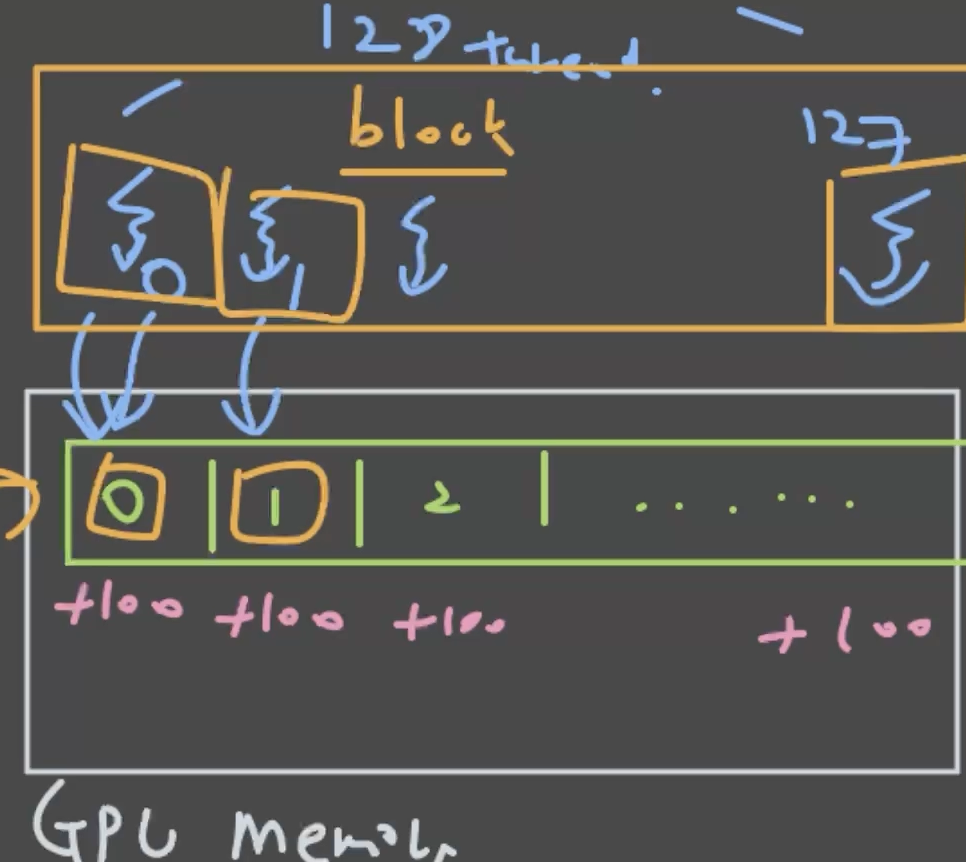
4. 커널실행
add100 <<<1, dataLength >>> (deviceData);
__global__ void add100(int32_t* data)
{
const int idx = threadIdx.x;
data[idx] = data[idx] + 100;
}
해당 부분을 CPU 코드로 만든다면 아래와 같습니다:
void cpuAdd100(int32_t * data)
{
for(int32_t idx = 0 ; idx < 128 ; ++idx)
{
data[idx] = data[idx] + 100;
}
}
CPU vs GPU 실행 방식의 차이:
- CPU: 하나의 스레드가 와서, for loop을 통해 element를 하나씩 연산을 합니다.
- GPU: 수천 개, 수만 개의 thread가 동시에 실행됩니다. 이 많은 thread가 하나의 kernel을 읽고 실행을 하는 개념입니다.
그러기 위해서 내가 어떤 thread인가를 알기 위한 특별한 변수가 필요합니다. 이를
const int idx = threadIdx.x;를 통해 받습니다.
그럼 각 thread별로 자기가 어떤 번호의 thread인줄 알 수 있고:
- thread 0번은 0번 index에
- thread 1번은 1번 index에
- thread 127번은 127번 index에 접근해서 100씩 올리는 연산을 하는 것입니다.
__global__ 키워드
그럼 이제 여기 특수 __global__이 붙는데, 이는 해당 커널은 device에서 실행되고, host에서 호출하는 커널이다라는 것을 명시하기 위한 문법입니다.
커널 호출 문법
커널 호출 부분 또한 특이합니다.
add100 <<<1, dataLength >>> (deviceData);
여기서 <<< >>> 꺽쇠가 붙습니다. 이는:
- 첫 번째: block 개수
- 두 번째: block당 thread 개수 지금 예제에서는 block을 하나만 launch 시키고, 그 하나의 block은 128개의 thread를 가지고 있습니다. CUDA 문법의 첫 시간이기 때문에, block이 무엇인지는 다음 시간에 설명하겠습니다.
어쨋든 해당 kernel을 실행할 때 128개의 thread를 실행시킨 것이고, 그 128개의 thread는 실행되면서 각자의 번호를 받고, data에 access를 합니다.
5. 동기화
이제 커널 연산이 끝나길 기다립니다.
cudaDeviceSynchronize();
CPU와 GPU는 독립적으로 동작하는 것이 가능하지만, 메인 프로세스는 CPU입니다. GPU는 아주 강력한 보조 연산장치라고 생각하시면 됩니다. 때문에, GPU 연산이 끝날 때까지 cudaDeviceSynchronize()를 통해 메인 CPU가 기다리는 파트입니다.
6. 메모리 복사 및 해제
cudaMemcpy(hostData, deviceData, dataLength * sizeof(int32_t), cudaMemcpyDeviceToHost);
cudaFree(deviceData);
delete [] hostData;
위 코드를 컴파일해서 실행시켜보면, 0부터 127까지의 숫자에 100이 모두 더해진 것을 확인할 수 있습니다.
정리
다시 정리하자면:
- Host 메모리 할당: CPU 메모리에 데이터 공간 확보
- Device 메모리 할당: GPU 메모리에 데이터 공간 확보
- Host → Device 복사: CPU에서 GPU로 데이터 전송
- 커널 실행: GPU에서 병렬 연산 수행
- 동기화: GPU 연산 완료까지 CPU 대기
- Device → Host 복사: GPU에서 CPU로 결과 전송
- 메모리 해제: 사용한 메모리 정리 이것이 CUDA 프로그래밍의 기본 패턴입니다. 다음 강의에서는 block과 grid의 개념에 대해 더 자세히 알아보겠습니다.
다음 강의
CUDA 문법에 익숙해지기 위해 조금더 복잡한 코드를 작성합니다