hardware devices
소개
이전 강의에서 하나의 블록당 1025개의 스레드를 생성하려고 했을 때 오류가 발생했습니다. 이는 CUDA의 하드웨어 제약사항 때문입니다.
핵심 포인트:
- CUDA의 제약사항은 하드웨어 아키텍처와 직접적으로 연관되어 있음
- GPU 모델마다 다른 성능 특성과 제한사항을 가짐
- 효율적인 CUDA 프로그래밍을 위해서는 하드웨어 특성을 이해해야 함
2. CUDA Device Properties API
CUDA는 각 GPU의 하드웨어 특성을 확인할 수 있는 API를 제공합니다.
주요 함수
cudaGetDeviceCount(&deviceCount);// GPU 개수 확인
cudaGetDeviceProperties(&prop, deviceId);// GPU 속성 확인
확인 가능한 주요 정보
- 메모리 정보: Global Memory, Shared Memory, Cache 크기
- 실행 구성: 최대 스레드 수, 블록 크기 제한
- 성능 지표: 클럭 속도, 메모리 대역폭
- 아키텍처 정보: Compute Capability, 멀티프로세서 개수
실습코드
#include <iostream>
#include <cuda_runtime.h>
#include <iomanip>
int main() {
int deviceCount;
cudaError_t error = cudaGetDeviceCount(&deviceCount);
if (error != cudaSuccess) {
std::cout << "CUDA error: " << cudaGetErrorString(error) << std::endl;
return -1;
}
std::cout << "Number of CUDA devices found: " << deviceCount << std::endl;
std::cout << "=================================" << std::endl;
for (int i = 0; i < deviceCount; i++) {
cudaDeviceProp prop;
cudaGetDeviceProperties(&prop, i);
std::cout << std::fixed << std::setprecision(2);
// Basic Device Information
std::cout << "Device " << i << ": " << prop.name << std::endl;
std::cout << " Compute Capability: " << prop.major << "." << prop.minor << std::endl;
// Memory Information
std::cout << " Global Memory: " << prop.totalGlobalMem / (1024*1024) << " MB (" << prop.totalGlobalMem / (1024.0*1024*1024) << " GB)" << std::endl;
std::cout << " Shared Memory per Block: " << prop.sharedMemPerBlock / 1024 << " KB" << std::endl;
std::cout << " L2 Cache Size: " << prop.l2CacheSize / 1024 << " KB" << std::endl;
std::cout << " Memory Bus Width: " << prop.memoryBusWidth << " bits" << std::endl;
std::cout << " Memory Clock Rate: " << prop.memoryClockRate / 1000 << " MHz" << std::endl;
// Execution Configuration
std::cout << " Registers per Block: " << prop.regsPerBlock << std::endl;
std::cout << " Warp Size: " << prop.warpSize << std::endl;
std::cout << " Max Threads per Block: " << prop.maxThreadsPerBlock << std::endl;
std::cout << " Max Thread Dimensions: (" << prop.maxThreadsDim[0] << ", " << prop.maxThreadsDim[1] << ", " << prop.maxThreadsDim[2] << ")" << std::endl;
std::cout << " Max Grid Size: (" << prop.maxGridSize[0] << ", " << prop.maxGridSize[1] << ", " << prop.maxGridSize[2] << ")" << std::endl;
// Performance and Architecture
std::cout << " Multiprocessor Count: " << prop.multiProcessorCount << std::endl;
std::cout << " Clock Rate: " << prop.clockRate / 1000 << " MHz" << std::endl;
// Key Features
std::cout << " Concurrent Kernels: " << (prop.concurrentKernels ? "Supported" : "Not Supported") << std::endl;
std::cout << " ECC Enabled: " << (prop.ECCEnabled ? "Yes" : "No") << std::endl;
std::cout << " Unified Addressing: " << (prop.unifiedAddressing ? "Yes" : "No") << std::endl;
std::cout << " Managed Memory: " << (prop.managedMemory ? "Yes" : "No") << std::endl;
// System Information
std::cout << " Integrated Memory: " << (prop.integrated ? "Yes" : "No") << std::endl;
std::cout << " PCI Bus ID: " << prop.pciBusID << std::endl;
std::cout << " PCI Device ID: " << prop.pciDeviceID << std::endl;
// Calculate memory bandwidth
float memoryBandwidth = 2.0 * prop.memoryClockRate * (prop.memoryBusWidth / 8) / 1.0e6;
std::cout << " Memory Bandwidth: " << memoryBandwidth << " GB/s" << std::endl;
std::cout << "=================================" << std::endl;
}
return 0;
}
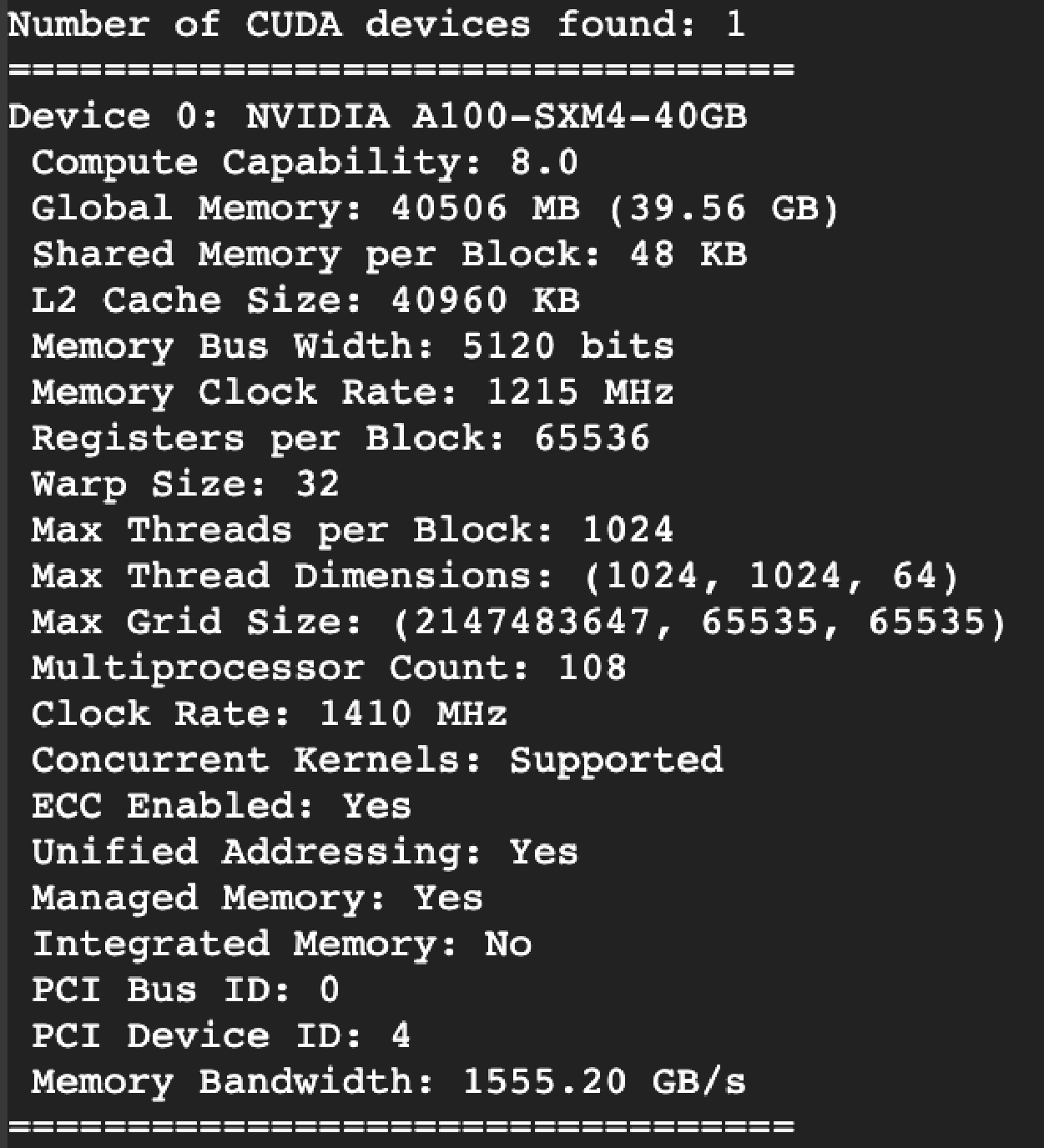
위 코드를 colab의 다른 두 GPU에서 실행해 보았습니다.
- Tesla T4 이제는 구형으로 볼수 있는 GPU입니다.
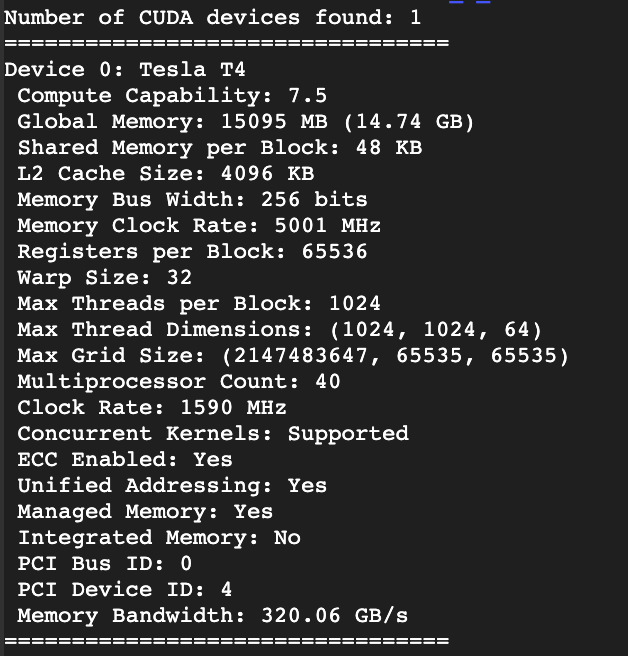
- A100 두 세대 뒤인 Property입니다